
[판다스 입문/산술연산] 시리즈 연산
2022. 10. 18. 12:41
목차
1. 시리즈 vs 숫자
2. 시리즈 vs 시리즈
3. 연산 메소드
시리즈 vs 숫자
Series객체 + 연산자(+, -, *, /) + 숫자시리즈 객체에 어떤 숫자를 더하면 시리즈의 개별 원소에 각각 숫자를 더하고 계산한 결과를 시리즈 객체로 반환한다.
# 예제 1-21
import pandas as pd
student1 = pd.Series({'국어': 100, '영어': 80, '수학': 90})
print(student1)
print('\n')
percentage = student1 / 200
print(percentage)
print('\n')
print(type(percentage))

시리즈 vs 시리즈
Series1 + 연산자(+, -, *, /) + Series2시리즈의 모든 인덱스에 대해 같은 인덱스를 가진 원소끼리 계산한다.
인덱스에 연산 결과를 매칭하여 새 시리즈를 반환한다.
# 예제 1-22
import pandas as pd
student1 = pd.Series({'국어': 100, '영어': 80, '수학': 90})
student2 = pd.Series({'수학': 80, '국어': 90, '영어': 80})
print(student1)
print('\n')
print(student2)
print('\n')
addition = student1 + student2
subtraction = student1 - student2
multiplication = student1 * student2
division = student1 / student2
result = pd.DataFrame([addition, subtraction, multiplication, division], index=['덧셈', '뺄셈', '곱셈', '나눗셈'])
print(result)

위 예제에서 인덱스로 주어진 과목명의 순서가 다르지만, 판다스는 같은 과목명(인덱스)를 찾아 정렬한 후 같은 과목명의 점수(데이터 값)끼리 연산한다.
# 예제 1-23
import pandas as pd
import numpy as np
student1 = pd.Series({'국어': np.nan, '영어': 80, '수학': 90})
student2 = pd.Series({'수학': 80, '국어': 90})
print(student1)
print('\n')
print(student2)
print('\n')
addition = student1 + student2
subtraction = student1 - student2
multiplication = student1 * student2
division = student1 / student2
print(type(division))
print('\n')
result = pd.DataFrame([addition, subtraction, multiplication, division], index=['덧셈', '뺄셈', '곱셈', '나눗셈'])
print(result)

연산을 하는 두 시리즈의 원소 개수가 다르거나, 시리즈의 크기가 같더라도 인덱스 값이 다를 수 있다.
<예제 1-23>처럼 어느 한 쪽에만 인덱스가 존재하고 다른 쪽에는 짝을 지을 수 있는 동일한 인덱스가 없는 경우 NaN으로 처리하게 된다.
한편 동일한 인덱스가 양쪽에 모두 존재하여 서로 대응되더라도 어느 한 쪽의 데이터 값이 NaN인 경우도 마찬가지로 연산 결과가 NaN이 된다.
연산 메소드
Series1.add(Series2, fill_value=n)시리즈 간의 연산에서 객체 사이에 공통 인덱스가 없거나 NaN이 포함되는 경우 연산 결과가 NaN으로 반환된다.
이런 상황을 피하려면 연산 메소드에 fill_value 옵션을 설정하면 된다.
# 예제 1-24
import pandas as pd
import numpy as np
student1 = pd.Series({'국어': np.nan, '영어': 80, '수학': 90})
student2 = pd.Series({'수학': 80, '국어': 90})
print(student1)
print('\n')
print(student2)
print('\n')
sr_add = student1.add(student2, fill_value=0)
sr_sub = student1.sub(student2, fill_value=0)
sr_mul = student1.mul(student2, fill_value=0)
sr_div = student1.div(student2, fill_value=0)
result = pd.DataFrame([sr_add, sr_sub, sr_mul, sr_div], index=['덧셈', '뺄셈', '곱셈', '나눗셈'])
print(result)
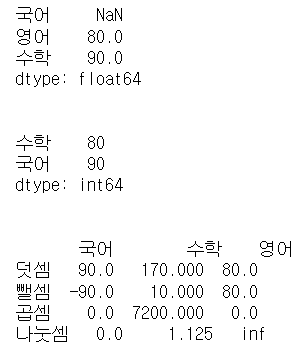
연산 메소드에 fill_value=0 옵션을 설정하여 NaN으로 계산된 결과들이 0으로 채워진 것을 볼 수 있다.
 |
|
'공부 > 파이썬 머신러닝 판다스 데이터 분석' 카테고리의 다른 글
| [데이터 입출력/외부 파일 읽어오기] (0) | 2022.10.20 |
|---|---|
| [판다스 입문/산술연산] 데이터프레임 연산 (0) | 2022.10.18 |
| [판다스 입문/산술연산] (0) | 2022.10.18 |
| [판다스 입문/인덱스 활용] (0) | 2022.10.14 |
| [판다스 입문/판다스 자료구조] 데이터프레임 (1) | 2022.10.14 |






